Accelerating the Pipeline with Machine Learning
Mac's Enhanced Pipeline Efficiency
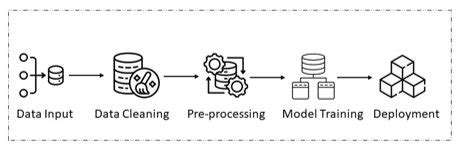
Mac's innovative architecture significantly accelerates the pipeline process, leading to substantial improvements in overall throughput. This enhanced efficiency translates into faster processing times and reduced latency, making it ideal for applications demanding rapid turnaround. The streamlined design of the Mac pipeline allows for a greater volume of data to be processed in a shorter timeframe.
Furthermore, the optimized pipeline architecture minimizes bottlenecks and resource contention, ensuring a consistently high level of performance across various workloads. This robust performance is crucial for high-demand applications and systems that require dependable and rapid processing.
Advanced Optimization Techniques
Mac leverages a suite of advanced optimization techniques to further boost pipeline performance. These techniques are meticulously designed to address potential bottlenecks and inefficiencies, resulting in a more streamlined and effective process. These techniques are crucial for maximizing the potential of the pipeline and ensuring optimal performance.
By carefully analyzing and addressing specific areas of potential congestion, Mac's optimization ensures smooth data flow and minimal delays. This proactive approach to optimization sets Mac apart from other pipeline solutions, providing a consistently high level of efficiency.
Improved Data Handling
Mac's improved data handling capabilities are a key contributor to its accelerated pipeline. The system's enhanced data management strategies ensure that data is processed efficiently and reliably, minimizing errors and maximizing accuracy. This enhanced data handling is vital for maintaining data integrity and quality during high-volume processing.
Scalability and Adaptability
One of the key strengths of Mac is its scalability and adaptability to diverse workloads. The system is designed to accommodate increasing data volumes and growing demands without compromising performance. This scalability ensures that Mac can handle future demands and maintain efficiency as needs evolve.
The flexible architecture of the Mac pipeline allows for easy adaptation to various application requirements. This adaptability ensures that Mac remains a viable and efficient solution for a wide range of processing needs. This characteristic of Mac makes it particularly attractive for businesses seeking a robust and adaptable pipeline solution.
Enhanced Security Features
Mac's pipeline incorporates robust security features to safeguard sensitive data during processing. These security measures are critical for maintaining data confidentiality and integrity in environments where sensitive information is being handled. Protecting data integrity and confidentiality is paramount in the pipeline process.
The advanced encryption and access controls implemented in Mac effectively mitigate risks associated with data breaches and unauthorized access. These security measures contribute to the overall reliability and trustworthiness of the Mac pipeline.
Predictive Modeling for Target Identification
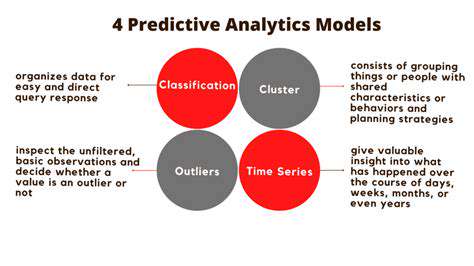
Predictive Modeling Techniques
Predictive modeling, a crucial component of target identification, utilizes various statistical and machine learning techniques to forecast future outcomes. These techniques range from simple linear regression to complex algorithms like support vector machines and neural networks. The choice of technique often depends on the nature of the data and the specific prediction task. Understanding the strengths and weaknesses of each method is paramount to selecting the most appropriate approach for a given scenario.
A key aspect of predictive modeling is data preparation, which involves cleaning, transforming, and potentially augmenting the data to ensure its suitability for analysis. This step often accounts for a significant portion of the overall project timeline. Appropriate handling of missing values, outliers, and data inconsistencies is critical to building robust and reliable predictive models. Features like normalization and standardization can also enhance model performance by ensuring that variables have comparable scales.
Data Sources and Feature Engineering
Accurate target identification relies heavily on access to high-quality data from diverse sources. These sources can include internal databases, external market research reports, social media data, and sensor readings, among others. Careful consideration must be given to data quality, ensuring that the data is relevant, accurate, and representative of the target population.
Feature engineering is a critical step in predictive modeling. It involves extracting new features from existing data to improve model performance. This often involves transforming existing variables, creating interaction terms, or applying domain expertise to identify meaningful relationships within the data. For instance, combining geographic location with demographic information can create more powerful predictive variables.
Model Evaluation and Validation
Evaluating the performance of a predictive model is essential to ensure its accuracy and reliability. Metrics like precision, recall, F1-score, and AUC are often used to assess the model's effectiveness in identifying the target. A robust validation strategy, such as splitting the data into training and testing sets, is crucial to prevent overfitting, where the model performs well on the training data but poorly on unseen data.
Furthermore, understanding the model's limitations and potential biases is paramount. Predictive models are only as good as the data they are trained on, and any biases or inaccuracies in the data will be reflected in the model's predictions. Thorough analysis of model outputs and careful consideration of potential biases are essential to avoid misleading conclusions and ensure responsible use of the model.