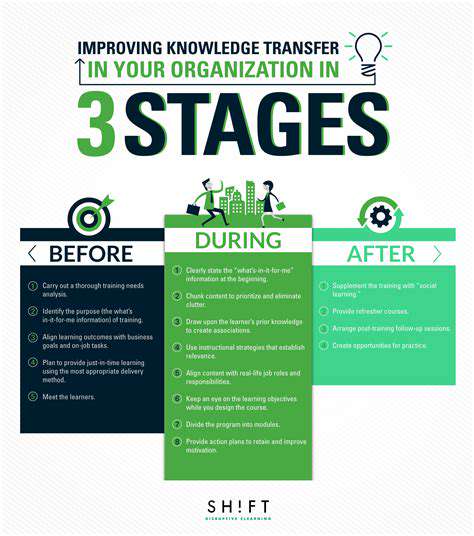
Boosting Assembly Efficiency with AR

Optimizing Instruction Pipelines
Efficient instruction pipelines form the backbone of high-speed assembly operations. To achieve peak performance, engineers must analyze each pipeline stage—fetching, decoding, and execution—to pinpoint inefficiencies. Strategic implementation of branch prediction and careful instruction scheduling often yields remarkable performance gains. When pipeline stalls are minimized and instruction throughput maximized, assembly programs can achieve near-theoretical execution speeds.
Advanced methods such as loop unrolling and instruction rearrangement frequently produce measurable improvements in pipeline utilization. These approaches enhance execution rates by decreasing pipeline interruptions and boosting the number of instructions handled during each clock cycle. A thorough understanding of instruction interdependencies enables developers to create more fluid and efficient execution patterns.
Leveraging Cache Memory
The strategic use of cache memory dramatically influences assembly performance. Skilled programmers design their code to ensure that critical data and frequently-used instructions remain readily accessible in cache, thereby minimizing latency. Mastery of cache hierarchy principles allows for smarter selection of data structures that complement the processor's memory architecture.
Effective cache utilization hinges on intelligent data placement strategies. By organizing information in memory to maximize both spatial and temporal locality, developers can substantially reduce cache misses. This optimization prevents unnecessary delays from slower memory accesses, delivering noticeable speed improvements.
Minimizing Branching Overhead
While branching instructions are fundamental for program control flow, they often introduce performance penalties in assembly code. Savvy programmers reduce branching frequency or implement alternative approaches like conditional moves when practical. In performance-critical sections, conditional moves frequently outperform traditional conditional jumps by eliminating pipeline disruptions.
Sophisticated branch prediction methods can mitigate much of the performance penalty associated with conditional logic. Optimized prediction algorithms minimize the costly pipeline stalls caused by mispredicted branches. Modern processor architectures incorporate increasingly sophisticated branch prediction units that developers can leverage for better performance.
Employing Parallel Processing Techniques
Parallel execution strategies offer substantial efficiency gains for assembly programs, particularly when handling complex calculations or large data sets. Implementing parallel instructions and distributing workloads across multiple processing units can slash execution times. Mastery of vector processing and SIMD (Single Instruction, Multiple Data) capabilities enables dramatic performance improvements for suitable algorithms.
Data Structure Considerations
Selection of appropriate data structures profoundly impacts assembly efficiency. Optimal choices minimize memory access delays and enhance locality, directly translating to better performance. A nuanced understanding of various structure types—including arrays, linked lists, and trees—allows developers to match data organization methods to specific computational requirements.
Cache-optimized data structures frequently deliver the most significant performance benefits. Thoughtful memory arrangement that reduces cache misses and maximizes cache line utilization often produces substantial speed improvements. Techniques like strategic padding and alignment to cache boundaries can yield unexpectedly large performance dividends.
Memory Management Strategies
Effective memory handling remains crucial for achieving peak assembly performance. Techniques including dynamic allocation, timely deallocation, and memory pool management help prevent fragmentation and maintain efficiency. Proper memory management practices prevent performance degradation and ensure optimal resource utilization throughout program execution.
Memory allocation methodology directly affects overall system performance. Selecting appropriate allocation strategies while considering alignment requirements and preventing leaks results in more robust and efficient assembly code. Deep understanding of memory hierarchy and access patterns separates mediocre implementations from high-performance solutions.
Utilizing Compiler Optimizations
Contemporary compilers incorporate sophisticated optimization capabilities that can dramatically enhance assembly efficiency. Leveraging these built-in optimizations frequently produces significant performance improvements without extensive manual code modifications. Familiarity with compiler-specific features and directives enables developers to generate highly optimized machine code.
Compiler optimizations often provide substantial time savings during development while improving final code quality. Proper use of architecture-specific compiler flags tailors generated code to target platforms, frequently producing assembly that's both faster and more maintainable than manually-optimized alternatives.