Boosting Algorithms: Adaboost and Gradient Boosting
Adaboost: A Gentle Introduction
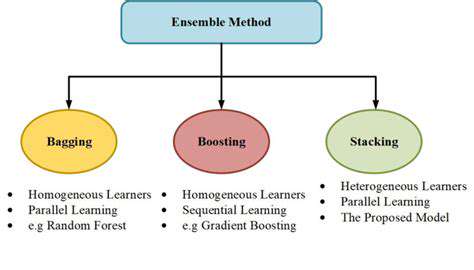
The Adaptive Boosting (Adaboost) algorithm pioneered the concept of transforming weak learners into a powerful collective. Its elegant weighting mechanism continuously adjusts focus toward problematic cases, creating a self-correcting learning process that often outperforms more complex standalone models. Particularly effective for noisy datasets, Adaboost demonstrates how strategic iteration can extract maximum value from simple base models.
Understanding Weak Learners
Adaboost's philosophy challenges conventional wisdom—it deliberately employs models only marginally better than random chance. These intentionally constrained models (often shallow decision trees) avoid overfitting while providing diverse perspectives. The algorithm's brilliance lies in its aggregation strategy, where numerous imperfect but complementary views combine to form remarkably accurate predictions.
The Iterative Nature of Adaboost
Each Adaboost iteration performs a sophisticated rebalancing act. Misclassified instances gain prominence in subsequent rounds, forcing new models to specialize in previously challenging cases. This dynamic weighting system creates a natural curriculum—the ensemble progressively tackles harder problems as basic patterns are mastered, mirroring effective human learning strategies.
Gradient Boosting: Building on Adaboost's Success
Gradient boosting represents an evolutionary leap, replacing Adaboost's weight adjustments with mathematical optimization. By framing the problem as gradient descent in function space, these algorithms can minimize arbitrary loss functions. This flexibility allows gradient boosting to handle complex regression tasks and custom optimization objectives that would challenge simpler boosting approaches.
Key Differences Between Adaboost and Gradient Boosting
The distinction between these methods lies in their error correction mechanisms. While Adaboost modifies instance weights, gradient boosting directly models residual errors. This fundamental difference gives gradient boosting greater flexibility but requires more computational resources. The choice between them involves trade-offs—Adaboost offers simplicity and efficiency, while gradient boosting provides superior performance on sufficiently resourced systems.
Applications of Boosting Algorithms
Modern boosting algorithms power cutting-edge applications across industries. In computer vision, they enable precise object detection in cluttered scenes. Natural language systems leverage their pattern recognition capabilities for nuanced sentiment analysis. Financial institutions depend on their predictive accuracy for credit scoring and algorithmic trading systems where marginal improvements translate to significant financial impact.
Choosing the Right Boosting Algorithm
Selection criteria extend beyond basic accuracy metrics. Adaboost's computational efficiency makes it ideal for prototyping and medium-scale applications. Gradient boosting variants dominate in data-rich environments where predictive performance justifies the additional computational overhead. The decision ultimately balances project constraints against performance requirements, with modern implementations like LightGBM and CatBoost providing optimized solutions for various scenarios.