Contrasting Supervised and Unsupervised Learning
Supervised Learning: A Guided Approach
Supervised learning algorithms are trained on labeled datasets, where each data point is paired with a corresponding output or label. This labeled data acts as a guide, instructing the algorithm on how to map inputs to outputs. The algorithm learns a function that can predict the output for new, unseen inputs based on the patterns it identifies in the training data. This process is analogous to a student learning from a teacher who provides examples and their correct solutions.
A key characteristic of supervised learning is its ability to generalize. After learning from the training data, a well-trained supervised learning model should be able to perform reasonably well on new, unseen data. This is crucial for real-world applications where the goal is to make predictions or classifications on data that the algorithm hasn't encountered before. This generalization ability is often evaluated using metrics such as accuracy, precision, and recall.
Unsupervised Learning: Discovering Hidden Patterns
Unsupervised learning, in contrast, deals with unlabeled data. The algorithm is tasked with finding patterns, structures, and relationships within the data without any pre-defined labels or outputs. This exploration can reveal hidden insights and knowledge within the data that might not be apparent to human analysts. Think of it like a detective trying to piece together clues to uncover a mystery without knowing the solution in advance.
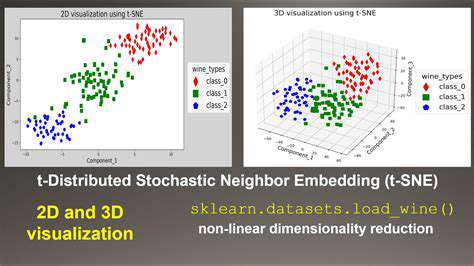
One common unsupervised learning technique is clustering, where the algorithm groups similar data points together based on their characteristics. Another is dimensionality reduction, where the algorithm simplifies the data by reducing the number of variables while retaining important information. These techniques can be invaluable for exploratory data analysis and understanding complex datasets.
Key Differences: Labeled vs. Unlabeled Data
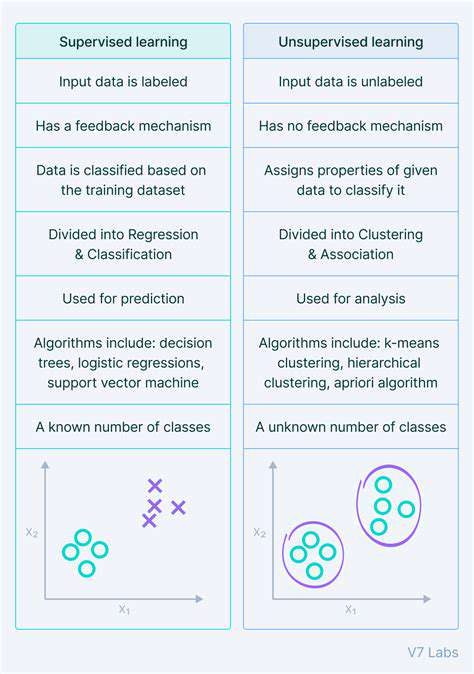
The fundamental difference between supervised and unsupervised learning lies in the presence or absence of labeled data. Supervised learning thrives on labeled data, which provides a clear target for the algorithm to learn from. Unsupervised learning, on the other hand, works with unlabeled data, allowing the algorithm to discover patterns and structures autonomously.
This difference in data characteristics leads to distinct learning approaches. Supervised learning algorithms aim to predict or classify new data points based on learned patterns, while unsupervised learning algorithms focus on understanding the inherent structure and relationships within the data. This fundamental distinction in approach significantly impacts the application and interpretation of the results.
Applications and Use Cases
Supervised learning finds widespread application in tasks such as image recognition, spam filtering, and medical diagnosis. By training on labeled datasets of images, emails, or patient records, the algorithm can learn to recognize patterns and make accurate predictions or classifications. These applications leverage the algorithm's ability to generalize from the training data to new, unseen instances.
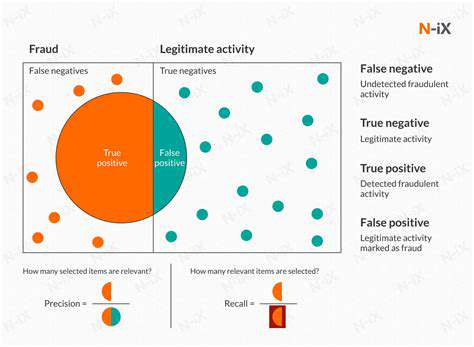
Unsupervised learning is useful for tasks like customer segmentation, anomaly detection, and recommendation systems. By identifying clusters of customers with similar characteristics, unsupervised learning can help businesses tailor their marketing strategies. Unsupervised learning also plays a crucial role in finding outliers or unusual patterns in data, which can be valuable for fraud detection or system monitoring.